
I am a Ph.D. student at Fei Xia Research Lab @ UC, Irvine, with research interests in Computational Imaging, particularly in imaging through scattering media and signal process. I have earned both my Bachelor’s and Master’s degrees from Huazhong University of Science and Technology (HUST) and Xi’an Jiaotong University (XJTU), respectively. I have previously interned and worked full-time at OPPO and VIVO as Machine Learning Engineer, where I was responsible for developing AI denoising models for smartphones.
📖 Educations
- 2025.09 - Present, Ph.D Student, Electrical Engineering and Computer Sciences, UC Irvine
 . Advisor: Prof. Fei Xia
. Advisor: Prof. Fei Xia - 2021.09 - 2024.06, Master of Engineering, Electronic Information, Xi’an Jiaotong Univerisity
 . Advisor: Prof. Jianbin Liu
. Advisor: Prof. Jianbin Liu - 2017.09 - 2021.06, Bachelor of Engineering, Electrical Engineering and Automation, Huazhong University of Science and Technology

💻 Experience
- 2024.07 - 2025.04, Machine Learning Engineer, YLab, OPPO Research Institute
 , China. Advisor: Prof. Lei Zhang
, China. Advisor: Prof. Lei Zhang - 2023.03 - 2023.05, Machine Learning Intern, VIVO Dept. of Image Effect
 , China
, China
🔥 News
- 2026.04, One of our papers has been accepted by the journal Advanced Photonics.
- 2025.11, Receiving the competitive Henry Samueli Endowed fellowship for Spring 2026.
- 2025.03, Joining Fei Xia Research Lab as a Ph.D student in Fall 2025.
- 2024.07, Joining YLab in OPPO Research Institute as an Image Algorithm Engineer.
📝 Selected Publications
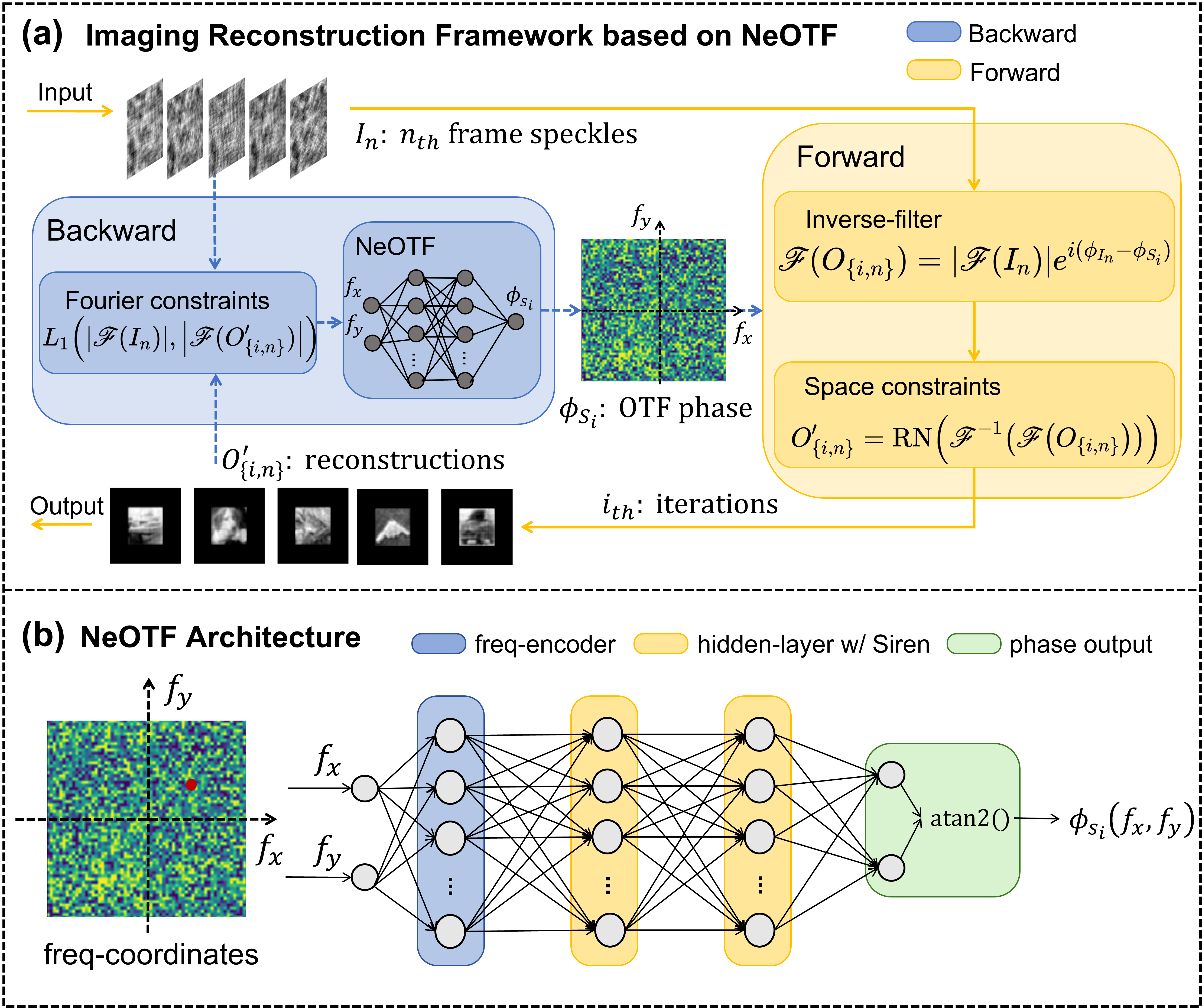
NeOTF: Guidestar-free neural representation for broadband dynamic imaging through scattering
Y Sun and F Xia.
- We introduce NeOTF, a framework that learns an implicit neural representation of the OTF. By applying multi-frame speckle intensities and Fourier-domain prior, NeOTF robustly retrieves the system’s OTF with high fidelity and efficiency.
- Both simulations and experiments demonstrate that NeOTF achieves superior accuracy and efficiency over conventional methods, establishing it as a practical solution for imaging through dynamic scattering with spatio-temporal memory effect.
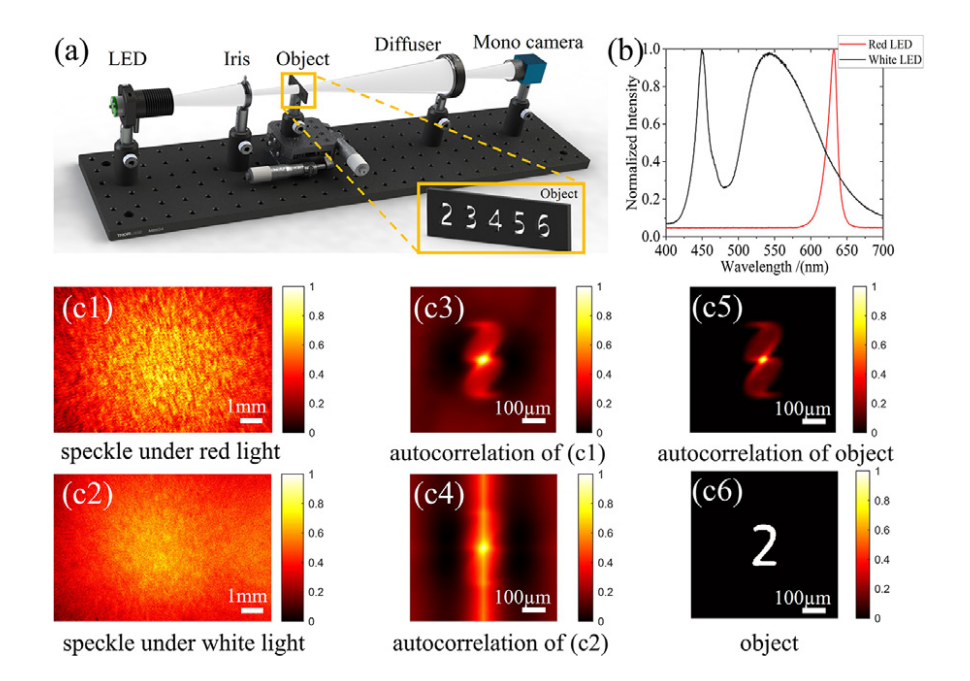
Non-invasive color imaging through scattering medium under broadband illumination
Y Sun, J Liu, H Chen, Z Xi, Y Zhou, Y He, H Zheng, Z Xu, Y Yuan
- Here, we propose a method for retrieving the optical transfer function with several speckle frames within memory effect range to image under broadband illumination. The method can be applied to image amplitude and colored objects under white LED illumination.
- The method based on the mulit-frame speckles provide more reliable results with faster convergence speed than single-shot imaging.


